Who will read your feed?
Today, agents already perform many of the repetitive tasks that I did manually a few months ago. For example, I have an agent that reads through news sites to find news that may be relevant for me. Sometimes I open the relevant article to read it, but usually I only read the summary the agent gives me. In the same way, an agent can follow all my social media at once and notify me when someone posts something relevant for me or when messages come in that I should follow up on. This saves me a lot of time, while I still get what is relevant. What I no longer get is ads, AI slop, and engagement bait, but more on that later.
Agents like this are easy to set up with, for example, OpenClaw or the Claude app. At the same time, this can save you many hours of doomscrolling. Remember that the platforms we use are optimized to make you spend as much time as possible on them. Have you, for example, experienced that you were just going to check a message on LinkedIn, and then ended up scrolling the feed for 20 minutes?
Let’s take a closer look at what it could mean if “everyone” starts using agents in this way. We use Facebook as an example.
- Facebook will no longer decide what I see. The timeline algorithm will no longer be in control.
- I will no longer see the ads shown on Facebook, unless the ad is so valuable that my agent believes I must see it. It is now my agent, with regard to my wishes and needs, that decides what I see, not Facebook.
- It no longer matters whether the information is shared on Facebook, LinkedIn, X, or other platforms. I will get it presented in exactly the same way.
Second-order effect
- Advertising on Facebook loses its value. This is how Facebook makes money today.
Third-order effect
- Facebook will try to stop agents from using their platform.
This, by the way, applies to all platforms that make money from ads. The question is what this leads to, and how we can avoid simply replacing one “walled garden” with a new one.
How do we avoid ending up in a new “walled garden”?
Now it is the agents that decide. Therefore, it is important that the agents work with the user, not with the provider of the underlying (AI) model.
OpenAI is now experimenting with ads in ChatGPT. This will give them incentives to keep you in ChatGPT as long as possible, so we are once again in the same model of engagement farming, just one layer higher in the stack. This only shifts who ends up with the value (OpenAI instead of Facebook), instead of making things better for users. This is the classic enshittification model.
There is a brighter path!
I believe that the business model we see today with subscriptions (without ads) can lead to aligned incentives between provider and user. For example, both the user and the provider will want a task to be solved as efficiently as possible, since it is a direct expense for the provider when users use their model. If we find a state where the user gets enough value from the model to keep the subscription, while the subscription is used as little as possible, that gives the provider an incentive to build the most efficient model possible. Remember that every time a user asks an agent to do something, it is a significant direct cost for the provider, unlike your Netflix subscription, for example, where there is a minimal cost for Netflix when you use your subscription.
But we do not know how this will develop. Therefore, I believe it is risky to become too dependent on a proprietary user interface, such as ChatGPT or the Claude app. Model providers want us to create agents and our personal context (memory, skills, instructions, etc.) through their user interfaces. They want to bundle their model together with your personal context and workflows, which will make it difficult for you to switch models later. I think this can put users in a poor position over time. A clear separation between “your things” (agents, memory, skills, instructions, etc.) and the model (the intelligence) solves this. Intelligence is off-the-shelf (a commodity). Do not let model providers trap you in their “walled garden”.
Instead, adopt open user interfaces such as Open WebUI, OpenCode, and OpenClaw. These are all solutions that give you an open user interface. Here you have full control over “your things” and can easily connect to the model you want. This makes it easy for you to switch models without affecting your workflow or your agents. This gives you a much stronger position and makes it easy to test newer, smarter, or cheaper models.
This is a development that several model providers naturally do not like (they want to lock users into their solutions). For example, among others, Anthropic (the provider of Claude) has blocked their subscriptions from being used through open solutions like those mentioned above. We can still use their models, but we have to pay for usage of their APIs, which can become very expensive.
Open models
Every week, there are now new and better open models, such as GLM, DeepSeek, Qwen, Kimi, and Gemma. These are models with open weights and can therefore be run by anyone, as long as they have good enough hardware. Even though several of these models are so large that they cannot easily be run at home, this means more providers can offer access to the models, which creates price competition and makes these models much cheaper than the closed alternatives, and a good alternative when using open user interfaces.
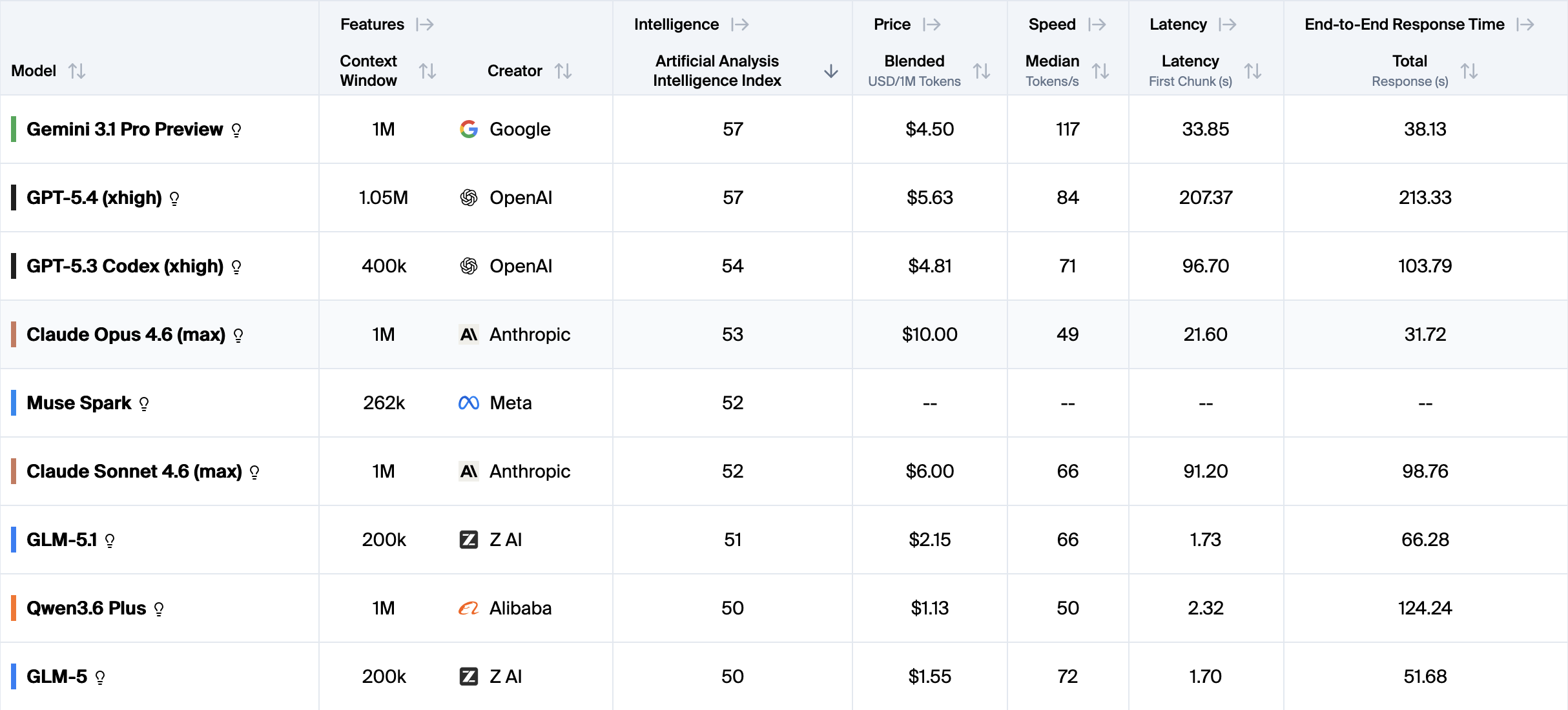
This is the list of the smartest models right now. Notice that GLM and Qwen are not far from the top.
For the agents we are talking about here, the ones that should find posts that are relevant for you, the smartest models are not needed either. I use an older version of GLM, and it works completely fine. When I switched my agent from Opus to GLM, I had to be a bit more specific about what it should do, but this is something I only need to set up once.
Another exciting development is that small open models are starting to appear that are also not far behind the proprietary top models. This makes it possible to run the whole agent locally. I am planning to write about this in a separate article later.
The future
I imagine that platforms like Facebook will start by doing their best to block access for agents (which they are actually already doing). The question is whether they can do this if an agent is seen as an extension of the user. Here, I hope regulation can help. In any case, I think it will be difficult for platforms to block access for agents. Agents can behave very much like users. They use the browser, they click and scroll, and so on.
If platforms like Facebook manage to block this, while it matters less which platforms people use, that will create fertile ground for new platforms that operate with completely different business models and for open networks such as Bluesky and Mastodon. Alternatively, the platforms we already use may find new ways to be more than just infrastructure (“pipes”).
I think the platforms that survive will be those that embrace this transition, even if they need to scale down and become less valuable companies with new business models. Or today’s platforms may disappear more and more and be taken over by open networks that do not need to make money.
Value shifts upward. Users need to make sure that the value goes all the way up to us instead of being captured by model providers. I hope for a future where we use services that do not profit from holding our attention.
The most important thing for users is to own their own agents and data, and to view intelligence as a commodity.